Go Code Notes
These are notes on writing good Go Code. Also see Go Developer Tooling. and Go Project Notes
Testing
Some notes on testing in Go. A lot of these notes came from Advanced Testing in Go (Hashimoto) (transcipt).
Types of tests
Copied from The Practical Test Pyramid except where noted.
- Unit tests - Your unit tests make sure that a certain unit (your subject under test) of your codebase works as intended. Unit tests have the narrowest scope of all the tests in your test suite. The number of unit tests in your test suite will largely outnumber any other type of test.
- Integration tests - test the integration of your application with all the parts that live outside of your application.
- Contract tests - make sure that the implementations on the consumer and provider side still stick to the defined contract. (also see Working without mocks).
- UI tests - testing UI code
- End-to-End tests - Testing your deployed application via its user interface. As they are complicated, they can be flaky and slow. (overlaps with acceptance tests)
- Acceptance tests - test that your software works correctly from a user's perspective, not just from a technical perspective - also see Introduction to acceptance tests
- Fuzz tests - See Go Fuzzing - a type of automated testing which continuously manipulates inputs to a program to find bugs. Relies on asserting properties about the code under test.
Types of test doubles
Copied from Working without mocks (and this whole online book is excellent).
- Stubs return the same canned data every time they are called
- Spies are like stubs but also record how they were called so the test can assert that the SUT calls the dependencies in specific ways.
- Mocks are like a superset of the above, but they only respond with specific data to specific invocations. If the SUT calls the dependencies with the wrong arguments, it'll typically panic.
- Fakes are like a genuine version of the dependency but implemented in a way more suited to fast running, reliable tests and local development. Often, your system will have some abstraction around persistence, which will be implemented with a database, but in your tests, you could use an in-memory fake instead.
Testing private and public APIs
Test files for a package's publicly visible API should be named <package>_ext_test.go and start with package <package>_test.
Test files for a package's internal API should be named <package>_int_test.go and start with package <package>
Comparison naming convention
Go's testing library wants you to do a lot of comparisons. The naming convention I want to use for these comparisons (taken from testify) is to call the value that I expect expectedXXX and always put it on the left side of the comparison, and the value that I actually got actualXXX, and always put it on the right side of the comparison:
if expectedThing != actualThing {
t.Fatalf("Oopsie")
}
Degrees of failure
The testing library has a couple ways to fail:
Failmarks the current test as failed, but continues the execution of the current test.Error/Errorfis equivalent toLog/Logffollowed byFail.FailNowmarks the current test as failed, and stops execution of the current test.Fatal/Fatalfis equivalent toLog/Logffollowed byFailNow.
testify
testify is super nice for comparing things because it writes most of my if statements for me. I can do:
// Mark current test as failed, but continue current test
assert.Equal(t, expectedValue, actualValue)
// Mark current test as failed, exit current test
require.Equal(t, expectedValue, actualValue)
Table driven tests
Test the same logic on different data!
Here's a simple example - note that in lieu of testing what's in the potential error, I simply assert that it's nil or not nil. For this particular test, this is "enough" to satisfy me. Other tests might require more detailed comparisons.
package main
import (
"errors"
"testing"
"github.com/stretchr/testify/require"
)
func AddOne(a int) (int, error) {
if a == 3 {
return 0, errors.New("We don't like the number 3")
}
return a + 1, nil
}
func TestAddOne(t *testing.T) {
tests := []struct {
name string
a int
expectedSum int
expectedErr bool
}{
{name: "first", a: 1, expectedSum: 2, expectedErr: false},
{name: "second", a: 2, expectedSum: 4, expectedErr: false},
{name: "third", a: 3, expectedSum: 0, expectedErr: true},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
actualSum, actualErr := AddOne(tt.a)
if tt.expectedErr {
require.Error(t, actualErr)
} else {
require.NoError(t, actualErr)
}
require.Equal(t, tt.expectedSum, actualSum)
})
}
}
When run, we see that the function is incorrect for the test data provided (or, more likely in this case, we need to correct the test data). testify gives us a super helpful error message.
$ go test ./...
--- FAIL: TestAddOne (0.00s)
--- FAIL: TestAddOne/second (0.00s)
main_test.go:37:
Error Trace: main_test.go:37
Error: Not equal:
expected: 4
actual : 3
Test: TestAddOne/second
FAIL
FAIL github.com/bbkane/hello_testing 0.173s
FAIL
Data files
When a test depends on a data file, Go will read it from a file path relative to the test. I like to stick my files for a test in a testdata/TestName.xxx file right next to the test. Then, within the test, I can ioutil.Readfile('testdata/TestName.xxx') to get the data. If each sub test in a table-driven test, needs a file, then I use testdata/TestName/SubTestName.xxx.
Golden files
Sometimes, I want to test that a function outputs the correct bytes - like a file, an HTTP response, or the --help output from the CLI parsing library I'm writing. In these cases, it's helpful to make the tests read an environmental variable, and write the bytes to a file when it is passed. Then I can manually read those files to ensure correctness, commit them, and make the test check the bytes generated to the file when the environmental variable is not set. My usage of this term comes from Advanced Testing in Go (Hashimoto), but I've also seen it called "snapshot" testing.
Golden file example (logos)
See logos for an example. I still haven't decided whether to turn this into a library or simply copy-paste it wherever.
Example tests
Code examples can be added to tests and also show up in the docs! See the Go blog for more details, or see my example below:
package main_test
import "fmt"
func ExampleExample() {
fmt.Println("hello!")
// Output: hello!
}
Errors
To some extent these error creation/handling ideas are tested in warg and other code, but I still have yet to prove other ideas. In particular, when prototyping I can get quite far eschewing these ideas and just using fmt.Errorf for everything, but fmt.Errorf errors can ossify in my project as it matures.
Guidelines
- An error should consist of a unique (to the repo) message and optionally more information specific to the problem. The message should be unique because Go errors do not include file information such as line numbers, so you need to grep for the error. Example:
ChoiceNotFound{Msg: "choice not found", Choices: []string{"a", "b", "c"}}. - Errors should not include information the caller already knows. Example: in
ChoiceNotFoundabove, the error does not need to contain the choice sent to the function that returns it because the caller already knows it. - Errors that do not need to include extra information can just use a package level sentinel
errors.New(...)var. Example:var ErrIncompatibleInterface = errors.New("could not decode interface into Value"). - Errors that do need to include extra information should not jam that into
fmt.Errorf, but instead use a struct with anError()method so the caller can retrieve the extra info. - Propagate errors by wrapping them - either with
fmt.Errorf(if you don't need to add more unique context), or with a struct using anUnwrapmethod (if you do need more unique context).
Unsolved problems and tradeoffs
- I wish errors had more file information like line numbers for debugging purposes. There ARE packages to add this, but I haven't chosen one.
- Error wrapping allows you to produce errors with one wrapped "child" error (like a chain of errors), but sometimes you'd like to produce an error with more than one "children" errors (like a tree of errors). An example of this is parsing, where you'd like to parse as much as you can and produce all the useful errors you can, so the user can fix all of those at once before they try to parse again. Once. again, there are packages to solve this, and some declined stdlib proposals like proposal: errors: add With(err, other error) error · Issue #52607 · golang/go.
- The approach above almost completely ignores API evolution concerns. In particular, what if I have a sentinel error, and the code changes, and I now need to add context to it? I'd need to change the type, which breaks the API. See Don’t just check errors, handle them gracefully | Dave Cheney for a great description of these problems and solutions. NOTE that this post precedes Go 1.13's error wrapping functions, which can (imo) be used to replace his
errorslibrary. No one uses my code, and I'm not the smartest man, so I've chosen simplicity of implementation with the possibility of API breakage over more complex but fewer API-breaking error implementations. I want to note this tradeoff explicitly as it's not the correct tradeoff for more public code.
References
- Working with Errors in Go 1.13 - The Go Programming Language - describes the mechanics of wrapping errors.
- Wrapping Errors the Right Way - by Hunter Herman - advocates for only including information the caller doesn't have.
- Designing error types in Rust is about Rust, but it advocates a couple ideas I really like, in particular the difference between libraries and applications, as well as that it's difficult to "overspecify" errors: "Feel free to introduce distinct error types for each function you implement. I am still looking for Rust code that went overboard with distinct error types."
- command center: Error handling in Upspin talks about Rob Pike's approach to errors in Upspin. Among other things, it talks about the tension between using errors to signal to users and to help programmers debug, as well as "operational traces" vs the more conventional stack traces other languages use. It also highlights that different projects should handle errors differently. Also see Failure is your Domain | Middlemost Systems for more thoughts on this blog post, as well as comparisonts to other ways to handle errors.
- Error Handling in Rust - Andrew Gallant's Blog - another Rust post, but it talks about error combinators, which might be useful to implement for some projects.
Tools
Generate Call graphs with crabviz
This might not be strictly more useful than "Show call heirarchy", but I'm having a lot of fun with the VS Code extension!
Visualize package imports with gopkgview
I find gopkgview useful to see issues (or the lack thereof) with my package imports. As a positive example, here's the import diagram of envelope:
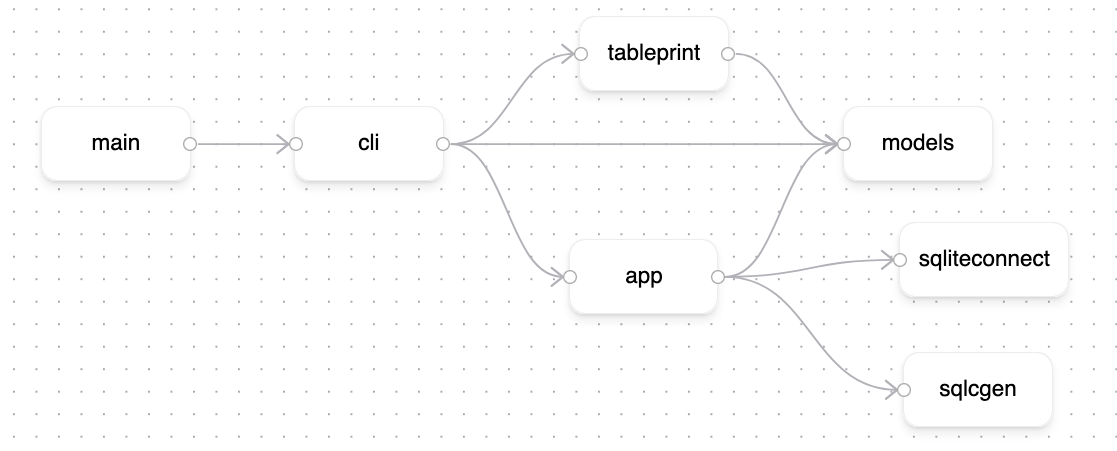
I was going for a somewhat layered architecture here, and that's clearly visible:
- the "presentation" layer (
cli) imports some helpers (tableprint), but uses theapppackage to talk to the storage packages (sqliteconnect,sqlcgen). Theapppackage is the only user of the storage packages - the
cli,tableprint, andapppackages use the shared set of types in themodelspackage to interface with each other. For example, to do a create operation, thecliparsesos.Argsand instantiates amodels.CreateXxxArgsand passes it to theapppackage. Theapppackage creates anXxx, then hands it back tocli.cli, then hands theXxxtotableprintto print.
Now, whether a layered architecture like this is worth the trouble is another conversation (expand below for that tangent), but the point is that I can analyze dependencies quite easily with this tool to investigate architecture issues.
There's also modgraphviz, which outputs a graphviz graph, but I'm not a huge fan of the auto-layout and filtering options.
TODO: move this to its own blog post...
Theoretical benefits I probably won't utilize for this project:
- I'm not planning on switching out another CLI library, or the sql bits, so I'm not sure they need to be self-contained.
- This project is small enough that I have confidence in correctness using mostly integration tests, so I don't need a ton of separation between packages for testing
Actual/planned benefits:
- I feel like everything is nicely structured and almost everything "has a home". There are a few helper functions in the
modelspackage, but 🤷. - I can fairly easily insert observability tooling "between" the layers. For example, to log every sql statement, I only have to mess with the app -> sql interface . Similarly, to log all CLI commands, I only have to mess with the CLI -> app interface. I don't need caching, but that would also be straightforward.
- I wrote this app to use for my projects, but ALSO to get experience with this architecture in a solo project. Projects at work already have an architecture and are always too big (and involve convincing teammates and postponing other work) to change things whenever I want to try a new pattern.
Actual drawbacks
- Large amounts of the code in this project are translating at the layers - to create an
Xxx, I define CLI flags for it, separately define an app-levelCreateXxxArgsfor it, separately define (actually generate withsqlc) a storage layerCreateXxxArgsfor it, then do the same thing in reverse to fill out themodels.Xxxstruct before passing it totableprint. This makes it a slog to build more commands and especially depressing to prototype them- if I want to add a new command (sayxxx delete), I'm writing lots of structs and translation code...
Maybe for the next project I'll try the "vertical slice" architecture folks find so freeing...